
Inside the Mind of an LLM: What Attention Heatmaps Tell Us About How AI Actually "Listens"

Attention Is All You Need
The paper that changed AI forever, visualized.
There's a phrase we casually toss around in the world of large language models: "Attention is all you need." It's the title of the 2017 Google Brain paper that fundamentally rewired how machines process language. But what does attention actually mean and how much has it evolved in just six years?
I ran an experiment to find out. And the results are worth seeing.
What Is Attention, Really?
Before we get to the heatmaps, let's ground the concept.
When you read the sentence "write a story about AI", your brain doesn't process each word in isolation. It instantly recognizes relationships, that story is what you're writing, that AI is what the story is about, and that write is the imperative binding everything together. You distribute your cognitive focus across the entire phrase.
Early language models couldn't do this. They were essentially sophisticated pattern-matchers that leaned heavily on whatever came first in a sentence. They were positionally biased, the first word carried disproportionate weight, and meaning dissolved toward the end of a phrase.
The Transformer architecture, introduced in "Attention Is All You Need", was designed to fix this. Instead of processing tokens sequentially (like RNNs and LSTMs), Transformers let every token attend to every other token simultaneously. The model learns which relationships matter and weights them accordingly.
But how well has that actually worked in practice? Let's look at the data.
The Experiment: GPT-2 vs GPT-OSS-20B
I took the same five-word prompt "write a story about AI" and ran it through two models:
Both are available on Hugging Face. I ran them on NVIDIA H100 GPUs in a Jupyter notebook, extracting and averaging the attention weights across all heads and layers to produce a single attention matrix for each model.
The setup is straightforward. Both models are loaded from Hugging Face using the transformers library, with output_attentions=True to observe the internal attention weights. I averaged across all layers and all heads to get a single representative attention matrix per model.
python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model with attention outputs enabled
model_name = "openai/gpt-oss-20b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, output_attentions=True)
# 5-word input
sentence = "write a story about AI"
inputs = tokenizer(sentence, return_tensors="pt")
# Forward pass- no gradients needed for inference
with torch.no_grad():
outputs = model(**inputs)
# outputs.attentions: one tensor per layer
# Shape per layer: (batch_size, num_heads, seq_len, seq_len)
attentions = outputs.attentions
# Average across all layers and all heads
avg_attention = torch.stack(attentions).mean(dim=(0, 1, 2))
# Convert to readable format
tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"][0])
attention_matrix = avg_attention.squeeze().tolist()
# Print the matrix
print("Tokens:", tokens)
print("\nAverage Attention Matrix:")
for token, row in zip(tokens, attention_matrix):
print(f"{token:>10} -> {[round(val, 3) for val in row]}")Swap model_name to "openai-community/gpt2" to run the same analysis on GPT-2. Everything else stays identical, which is exactly the point. Same prompt, same code, completely different attention behavior.
GPT-2 output:
Tokens: ['write', 'Ġa', 'Ġstory', 'Ġabout', 'ĠAI']
Average Attention Matrix:
write -> [1.0, 0.0, 0.0, 0.0, 0.0 ]
Ġa -> [0.904, 0.096, 0.0, 0.0, 0.0 ]
Ġstory -> [0.757, 0.144, 0.1, 0.0, 0.0 ]
Ġabout -> [0.682, 0.092, 0.116, 0.11, 0.0 ]
ĠAI -> [0.676, 0.049, 0.05, 0.105, 0.121]GPT-OSS-20B output:
Tokens: ['write', 'Ġa', 'Ġstory', 'Ġabout', 'ĠAI']
Average Attention Matrix:
write -> [0.148, 0.0, 0.0, 0.0, 0.0 ]
Ġa -> [0.142, 0.133, 0.0, 0.0, 0.0 ]
Ġstory -> [0.102, 0.076, 0.139, 0.0, 0.0 ]
Ġabout -> [0.089, 0.06, 0.117, 0.131, 0.0 ]
ĠAI -> [0.077, 0.016, 0.036, 0.054, 0.161]
The triangular structure (zeros above the diagonal) is expected, this is causal masking at work. Each token can only attend to itself and the tokens that came before it, not the future. What changes between 2019 and 2025 is how that available attention is distributed, concentrated on position 1, or spread meaningfully across the whole phrase.
And here's the visual comparison:
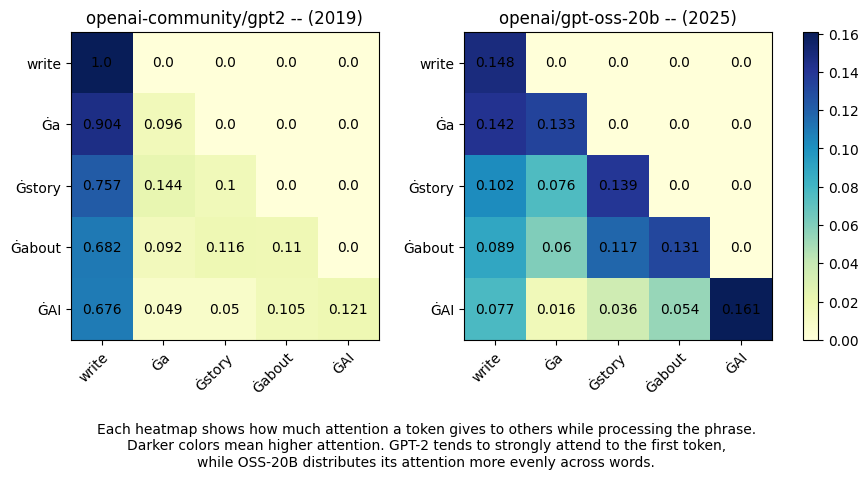
The difference is striking.
What the Heatmaps Reveal
GPT-2 (2019): The first column is almost entirely dark deep blue across the board. Every token is paying enormous attention to "write", and almost nothing else. The attention scores for "story" and "AI" are negligible. The model is anchored to the beginning of the sentence and barely processes the rest.
GPT-OSS-20B (2025): The matrix looks completely different. Attention is distributed diagonally, each token attends meaningfully to the tokens that came before it, and the diagonal itself (a token attending to itself) carries weight without dominating everything else. "story" attends to "story", "AI" attends to "AI", and the relationships between them are real, not washed out.
In practical terms: the newer model actually understands the prompt as a whole. The older model just remembered how it started.
Why Early Models Struggled With Attention Across a Sentence
This wasn't just a GPT-2 problem. Pre-Transformer architectures - RNNs, LSTMs, GRUs processed language sequentially. Each token was processed one at a time, and information from earlier tokens had to be "carried" through hidden states. By the time you reached the end of a long sentence, the signal from the beginning had often degraded or vanished entirely. This was called the vanishing gradient problem, and it fundamentally capped how much context a model could hold.
Even the Transformer's early implementations had limitations. The attention mechanism existed, but with fewer parameters, fewer layers, and less training data, models like GPT-2 still defaulted to statistical shortcuts over-relying on the first token because that's what the training distribution rewarded most often.
With scale came something different: the model began learning genuine semantic relationships rather than positional shortcuts. More parameters meant more capacity to model the rich dependencies between words. More data meant exposure to enough context that shallow heuristics stopped being sufficient.
The heatmap you're looking at isn't just a visualization of a matrix. It's a visualization of a model learning to think in context.
The Human Parallel: Attention Isn't Unique to Machines
Here's something worth sitting with.
When you interact with a language model you type a prompt and get a response, you probably assume the model understood you the way you meant to be understood. That the words you chose carried exactly the weight you intended. But that assumption has a hidden flaw: the model doesn't attend to your prompt the way you attended to it when you wrote it.
You emphasized certain words in your mind. You assumed certain background knowledge. You weighted some phrases as throwaway qualifiers and others as the crux of your request. The model read the same characters, but it attended to different things based on everything it learned during training, and the specific way its attention mechanism weighted each token against the others.
This is, remarkably, the same problem that exists between humans.
You tell a colleague something important in a meeting. You're thinking about one thing. They're attending to something slightly different maybe the tone you used, maybe a word that triggered an association, maybe the last sentence instead of the first. The message sent is not always the message received, because attention is personal. Every listener, human or model brings their own learned patterns of what matters.
What makes this insight powerful is that it reframes how we should think about prompting. It's not just about what you say to a model. It's about which parts of what you say the model will actually attend to and whether that matches the parts you care most about. A weaker model might fixate on the verb at the start of your prompt. A stronger model might catch the nuance buried three clauses in.
The evolution from GPT-2 to GPT-OSS-20B isn't just a benchmark improvement. It's the model getting better at listening in the same way that a great conversationalist isn't just someone who hears your words, but someone who picks up on what you actually meant.
Why This Architecture Scales So Well
The reason Transformer-based attention keeps improving with scale comes down to a few elegant properties of the mechanism itself.
Parallelism. Unlike RNNs, Transformers process all tokens simultaneously. This means training on massive datasets is actually feasible, you're not waiting for sequential computation to finish before moving to the next token.
Multi-head attention. Rather than learning a single set of attention weights, Transformers learn multiple attention patterns simultaneously, different heads can specialize in syntax, semantics, coreference, positional relationships, and more. With more parameters, more heads can develop richer specializations.
Global receptive field. Every token can attend to every other token directly, regardless of distance. There's no decay of information over sequence length. A word at position 500 in a long document can directly attend to a word at position 1, something RNNs could never reliably do.
Depth compounds. Each layer of a Transformer refines the representations built by the layer below it. Early layers might resolve simple syntactic relationships; deeper layers encode abstract semantic meaning. Stack more layers, train on more data, and the model builds increasingly sophisticated internal representations of language.
This is why scale has produced such dramatic improvements in language understanding. The Transformer architecture has a natural ceiling that's very, very high and we're still climbing it.
The Takeaway
Six years. One architecture. A fundamental shift in how machines process meaning.
GPT-2 saw a sentence and anchored to its beginning. GPT-OSS-20B sees a sentence and understands it as a web of relationships, each word in conversation with the others, each carrying its proportional weight.
That shift from positional bias to contextual understanding is why modern LLMs can write coherent long-form content, reason across multiple facts in a document, and function as agents that do more than predict the next word.
It's also a mirror for something deeply human: the quality of any conversation, between people or between a person and a model, depends entirely on what each party chooses to pay attention to.
The models are getting better at listening. The question is whether we're getting better at speaking to them.
Ran on NVIDIA H100 GPUs Models loaded from Hugging Face using the Transformers library. Code available in the Jupyter notebook screenshots and pasted separately above.
References & Further Reading
Core Papers
[1] The Transformer Architecture Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention Is All You Need. NeurIPS 2017. → arxiv.org/abs/1706.03762
[2] GPT-2 Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners. OpenAI Blog. → openai.com/index/better-language-models
[3] GPT-OSS-20B (Hugging Face) → huggingface.co/openai/gpt-oss-20b

[4] GPT-2 (Hugging Face) → huggingface.co/openai-community/gpt2

Tools & Infrastructure
[5] HuggingFace Transformers Library Wolf, T., et al. (2020). Transformers: State-of-the-Art Natural Language Processing. → huggingface.co/docs/transformers

[6] PyTorch → pytorch.org

Suggested Reading
- The Illustrated Transformer - Jay Alammar's visual breakdown of how Transformers work (the best beginner resource on the web)
- The Annotated Transformer - Harvard NLP, line-by-line walkthrough of the original paper in code
- Attention? Attention! - Lilian Weng's deep dive into attention mechanisms
